其他内容
现在你已经完成了本教程的大部分核心内容:实例、设备、交换链、图形管线、纹理、模型、同步、计算着色器,以及若干进阶特性。
但 Vulkan 远不止这些。与其把剩余内容零散地列成“杂项”,不如把它们整理成一份更清晰的后续学习路线。
本章不会继续给出完整实现,而是概括每个方向的用途、价值和学习重点,帮助你决定下一步应该深入什么。
渲染架构进阶
1. 多 Pass 渲染
很多实际渲染效果都不是一次绘制完成的,而是拆成多个 Pass。
以“阴影映射”为例,常见做法是:
- 先从光源视角渲染深度图。
- 再从摄像机视角渲染场景,并在着色器中采样这张深度图来计算阴影。
类似的思路还包括后处理、环境贴图预计算、反射探针、屏幕空间效果等。学会组织多个 Pass,往往比继续堆单个管线的细节更重要。
2. 子通道与延迟渲染
如果你继续使用传统渲染通道模型,那么子通道和输入附件仍然值得了解。
一个经典示例是简单的“延迟渲染”:
- 第一个子通道输出法线、颜色、深度等 G-Buffer 数据。
- 第二个子通道读取这些附件,对每个像素执行光照计算并输出最终结果。
不过需要注意,子通道并不总能带来性能收益。它在移动平台或特定 Tile-Based GPU 上往往更有价值,而在现代桌面 GPU 上,多个独立 Pass 配合显式屏障也很常见。
3. 模板测试与特殊区域渲染
我们在深度缓冲章节提到过模板测试,但还没有真正使用它。
模板测试常用于:
- 镜面或传送门区域
- 描边效果
- 只在特定区域中允许后续绘制
- 延迟渲染中的遮罩控制
例如,你可以尝试实现一个简单的“镜面区域”:
- 第一次绘制时,仅写入模板值,标记镜面区域。
- 第二次绘制时,只允许模板测试通过的像素被写入,从而把镜像场景限制在镜面内。
CPU 并行与命令录制
GPU 本身就擅长并行执行任务,因此所谓“多线程渲染”,通常指的是 CPU 端的多线程准备工作。
1. 次级命令缓冲
从命令池分配命令缓冲时,level 可以是 ePrimary 或 eSecondary。
次级命令缓冲不能直接提交到队列,但可以被主命令缓冲执行。
这使得你可以把大场景的录制工作拆成多个模块,例如:
- 静态场景
- 透明物体
- UI
- 阴影绘制
不过需要注意,次级命令缓冲并不一定天然更快。它的主要价值是改善录制组织方式,并为多线程录制提供更自然的拆分单位。
2. 并行命令录制
Vulkan 的命令池不是线程安全的,因此更常见的做法是:
- 每个工作线程拥有独立的命令池。
- 每个线程从自己的命令池中分配并录制命令缓冲。
- 最终由主线程统一组织提交顺序。
这类优化通常在场景复杂、Draw Call 数量很多时才明显有收益。对于小项目,先把资源生命周期和同步关系设计清楚,通常比过早引入线程池更重要。
性能与资源管理
1. 间接绘制
之前的示例中,绘制参数由 CPU 在录制命令时直接给出。
而间接绘制会把这些参数放进 GPU 缓冲区中,再由命令如 drawIndirect、drawIndexedIndirect 读取。
这样做的好处是:
- 减少 CPU 参与程度
- 便于 GPU 生成或筛选绘制列表
- 更适合实例化、大场景和剔除系统
如果再结合计算着色器做可见性剔除,就能进一步形成 GPU-Driven Rendering 的基本雏形。
2. 稀疏资源
稀疏资源允许你只为资源的一部分区域绑定物理内存,而不是一次性把整块资源全部分配出来。
它适合处理:
- 超大纹理
- 虚拟纹理
- 大型体素或地形数据
- 流式加载资源
这是非常高级的话题,通常只有在资源规模大到普通内存分配方案难以承受时才值得引入。
3. 内存分配器
在前面的章节中我们已经多次提到,不应为每个缓冲区或图像单独分配一块 vk::DeviceMemory。
在实际工程中,更常见的做法是使用专门的分配器进行子分配。最常见的现成方案就是 Vulkan Memory Allocator(VMA)。
建议你至少掌握两件事:
- 如何使用现成分配器管理缓冲区和图像。
- 为什么线性分配、空闲链表、块管理和碎片整理会影响长期运行时的性能与稳定性。
离屏渲染与图像处理
最简单的离屏渲染是不创建窗口和交换链,而是直接把结果渲染到手动创建的图像中,然后再把图像保存为文件。
这类技术常用于:
- 服务器端渲染
- 自动化截图
- 资源预处理
- 生成 G-Buffer、Shadow Map、Environment Map
你可以尝试:
- 去掉交换链和窗口表面。
- 使用自建图像作为颜色或深度输出。
- 在渲染完成后把图像拷回主机并保存为本地文件。
在此基础上,还可以继续研究图像后处理、色调映射、HDR 工作流等内容。
图形着色器进阶
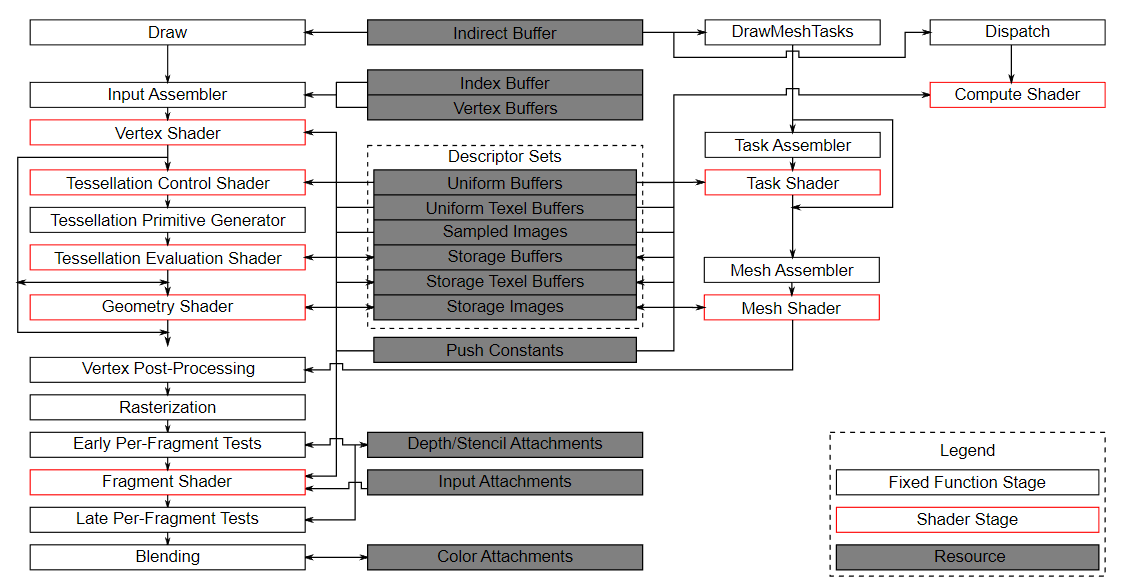
1. 几何着色器
几何着色器位于顶点处理之后,可以基于输入图元生成新的图元,或直接丢弃输入图元。
它能完成一些很灵活的效果,例如:
- 法线可视化
- 简单外扩
- 程序化生成线框或辅助几何
但需要注意,几何着色器在很多平台上的性能并不理想,因此现代实时渲染中并不是首选方案。
2. 细分着色器
细分着色器用于在 GPU 上细化几何体,适合曲面细分、地形细节增强等场景。
在 Vulkan 中,它由三部分组成:
- 细分控制着色器(Tessellation Control Shader)
- 细分图元生成器(固定功能阶段)
- 细分求值着色器(Tessellation Evaluation Shader)
它并不是“生成控制点”,而是根据控制点和细分因子生成更密集的采样点,再由求值着色器输出最终顶点数据。
3. 任务着色器与网格着色器
任务着色器和网格着色器是更现代的图形管线编程模型,通常通过相关扩展提供,而不是 Vulkan 1.2 的通用核心能力。
它们的目标是用更灵活的方式取代传统的顶点输入装配、几何着色器等部分流程,特别适合:
- GPU 驱动渲染
- 大规模实例化
- 程序化几何生成
这并不意味着它们“仅用于间接渲染”,但它们往往会和 GPU 驱动的任务生成方式配合使用。
计算着色器进阶
1. 原子操作
计算着色器中的调用是并行执行的,当多个线程需要修改同一块数据时,就必须使用原子操作来避免数据竞争。
典型场景包括:
- 统计直方图
- 构建计数器
- 并发分配输出位置
- 粒子系统中的全局计数
2. 共享内存
共享内存是工作组内部线程之间进行高速通信的关键机制,通常位于片上缓存,速度远高于全局显存访问。
需要注意的是,它只在单个工作组内部共享,跨工作组并不能直接访问同一块共享内存。
3. 子组操作
子组(Subgroup)表示 GPU 执行并行计算时更细粒度的一层执行单元,通常与硬件上的 SIMD 或 Wavefront/Warp 概念相近。
正确使用子组操作可以显著提升某些算法的效率,例如归约、扫描、投票和矩阵计算。
光线追踪
Vulkan 的光线追踪通常围绕三类核心对象展开:
- 加速结构
- 光线追踪管线
- 着色器绑定表
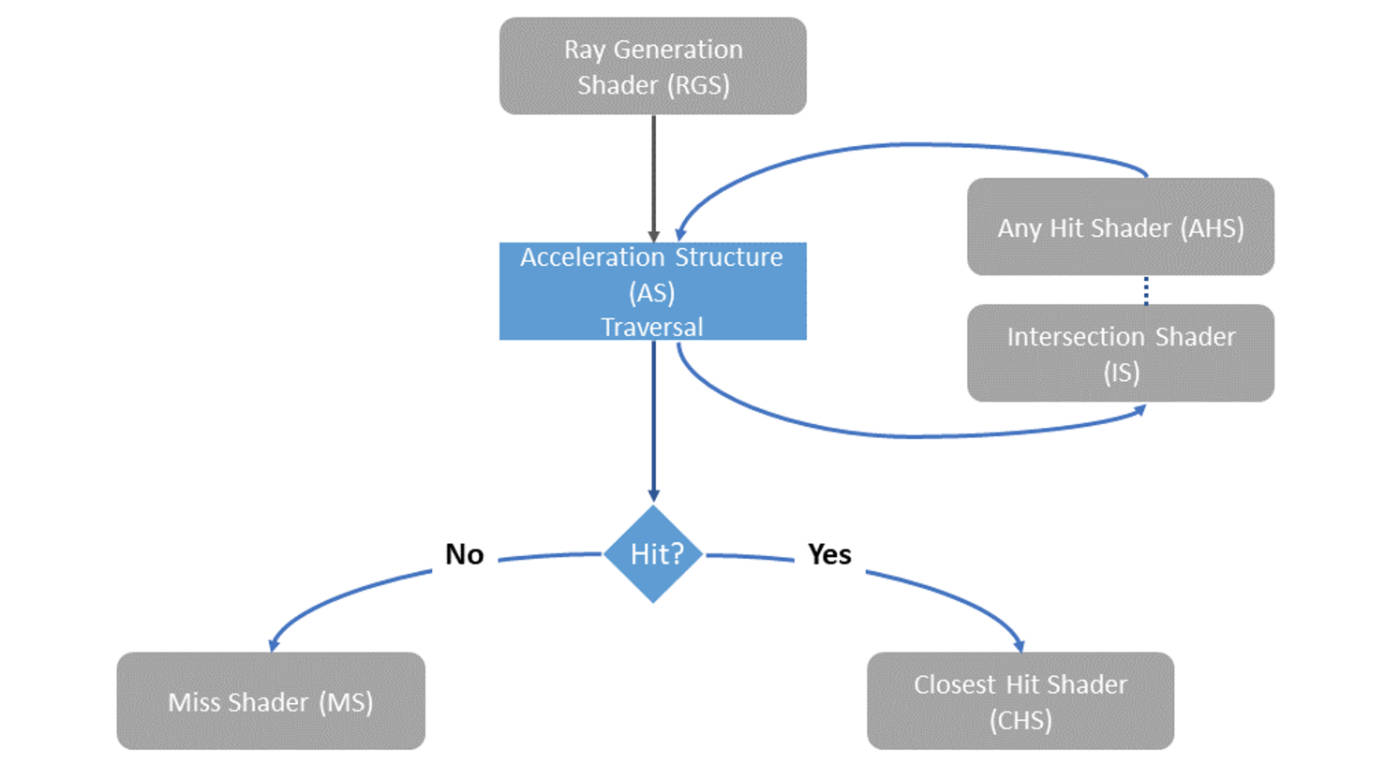
加速结构用于组织场景几何,通常是 BLAS/TLAS 这样的层次结构,以便快速完成光线求交。 光线追踪管线则包含多类着色器,用于处理发射、命中、未命中以及可能的递归逻辑。 着色器绑定表用于把几何体、实例和具体着色器记录关联起来。
这部分内容已经明显超出入门教程范围,但如果你已经完成本教程的大部分章节,它会是一个很自然的下一步方向。
你可以在官方文档中找到光线追踪的相关教程。
多视口与多视图
“多视口”通常指在一次绘制中配置多个 viewport/scissor 区域,而“多视图(Multiview)”则更常用于 VR 这类需要同时为多个观察视角生成图像的场景。
二者相关,但不是同一个概念。
如果你计划继续做:
- 分屏渲染
- 编辑器多窗口预览
- 立体渲染
- VR/AR
那么这两个方向都值得分别学习。